

人手不足の問題を解決する手段として注目されている「OCRとRPA」の連携
働き方改革や業務改善が提唱される中、紙文書やPDF画像のテキストを手動で電子データ化する業務は今も少なくありません。
手動で紙文書などの情報を入力する作業は、手間がかかるだけでなく入力ミスなども生じ、非効率を作り出す要因になっています。
このような業務を効率的にするためには、紙文書のテキストを自動認識してデータ処理を行うOCR(Optical Character Recognition)技術を取り入れることが最も有効であり、また、OCRとRPA(Robotic Process Automation)を連携して自動化することで、生産性の向上と業務効率化を実現することができ、人手不足の問題を解決する手段としても注目されています。
ImageGear OCR とは
ImageGear OCR SDK は、C、C ++、C# にて簡単にOCR 機能を実装することが可能です。
ImageGear OCR SDK は、英数字版のみならずアジア版も提供しており、日本語以外に中国語、韓国語などをサポートしております。
サンプルは、C#、VB.NET 、C およびC ++ 用を提供しており、開発者はサンプルコードを参考にするだけで簡単にOCR 機能をアプリケーションへ実装することができます。
- 米国では、西洋とアジア両方を含む100以上の言語に対応しております。現在販売中の英数字版以外をお求めの方は、弊社営業までご相談下さい。
高機能OCR
ImageGear OCR SDK は、認識率を上げる為に自動ゾーニングとセグメンテーションにより、ユーザーは次のことが可能になります。
- 処理のためにページを個々のゾーンに自動的にセグメント化が可能
- フロー、テーブル、またはグラフィックに基づいて、特定されたゾーンにタイプを割り当てる事が可能
- 高度な技術を使用してテーブルを検出し、データ結果の再構築を向上させる画像全体、またはページの個々の領域を処理する事が可能
- ユーザーによるゾーンの定義、ファイルからのロード、またはエンジンにより自動検出する事が可能
- フルページの光学式文字認識(OCR)を提供します。ImageGear の自動言語検出(.NET OCRライブラリのみ)機能は、OCR 補完を可能にします。
定義済みおよびカスタマイズ可能な辞書
ImageGear のOCR SDK は文書をスキャンする際、事前定義された辞書とデータ辞書を使用しております。ImageGear は、それぞれが特定の辞書にある異なる言語に対して、高度なスペルチェックを使用します。17の辞書にはそれぞれ100,000 から200,000 のエントリが可能であり、OCR の正確性を向上させます。また、必要に応じた値でユーザー辞書を定義して検証をカスタマイズし、正規表現を使った結果を検証することもできます。
OCR結果
ImageGear OCR SDK は、すべてのデータをUnicode フォーマットで処理します。データ出力は次のような複数の出力オプションを使用して、特定のコードページ用にフォーマットできます。
- PDF 上の画像
- テキストベースのPDF
- Microsoft Office(Word、Excel、Powerpoint)
- RTF
- HTML
- XML
OCR スキャンのサンプルデータ
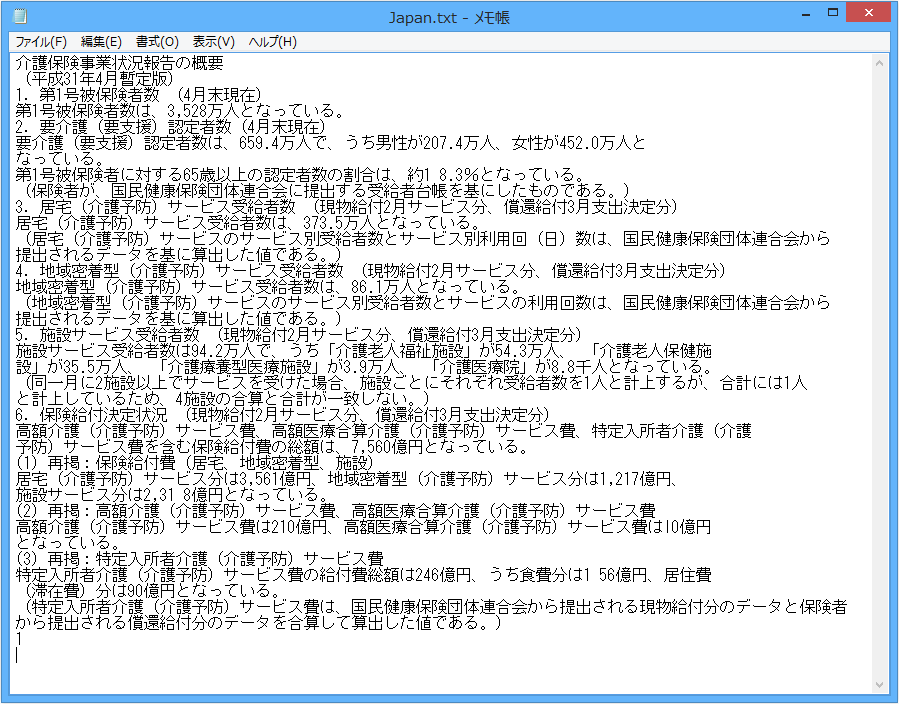
日本語
スキャン元のPDFファイル

※クリックで拡大
OCRスキャン後のテキストファイル
※クリックで拡大
中国語
スキャン元のPDFファイル
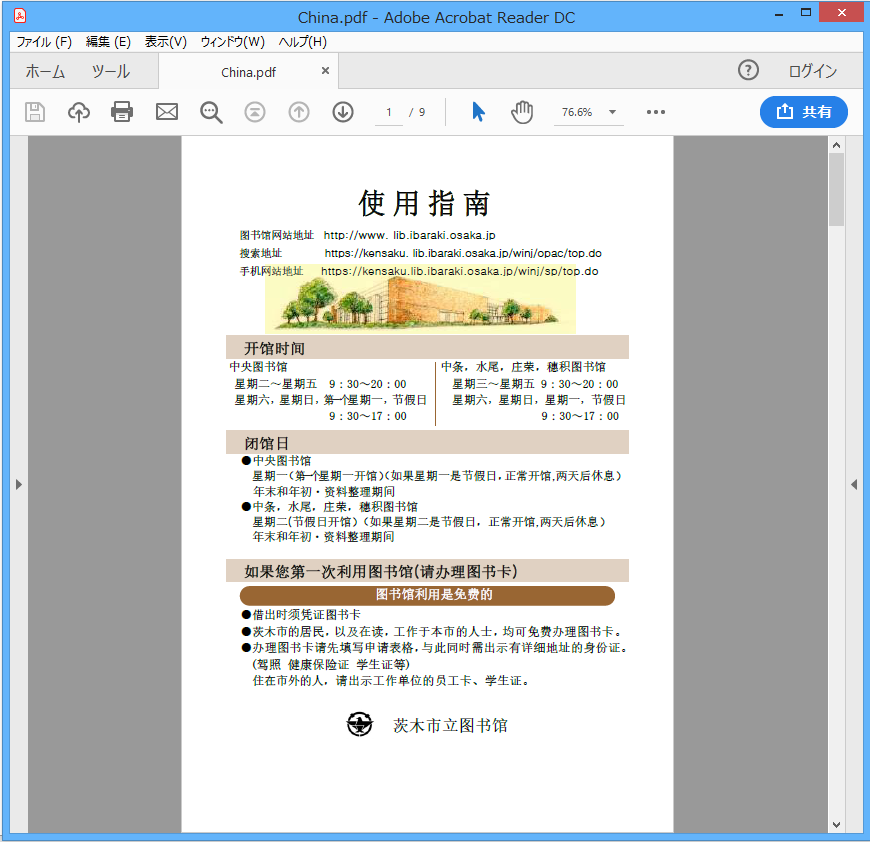
※クリックで拡大
OCRスキャン後のテキストファイル
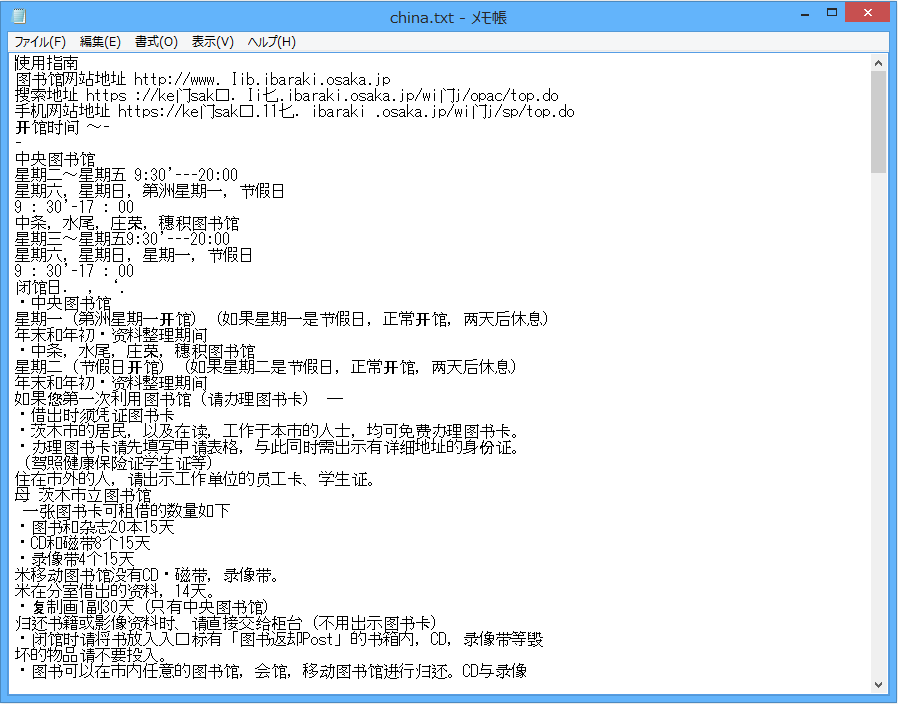
※クリックで拡大
韓国語
スキャン元のPDFファイル
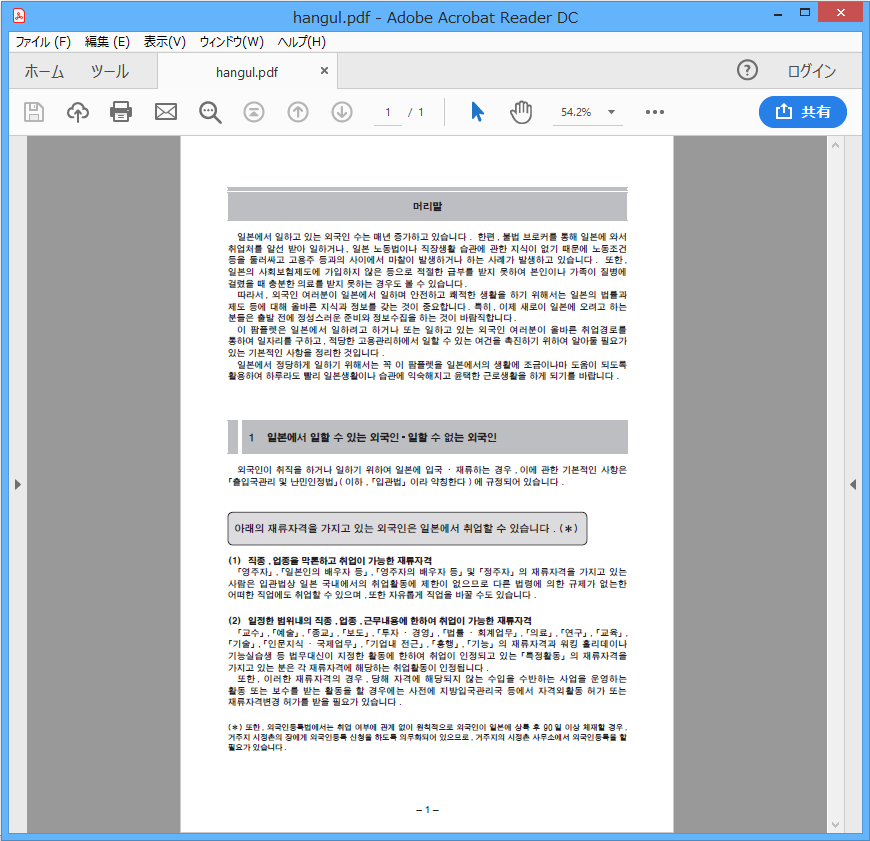
※クリックで拡大
OCRスキャン後のテキストファイル
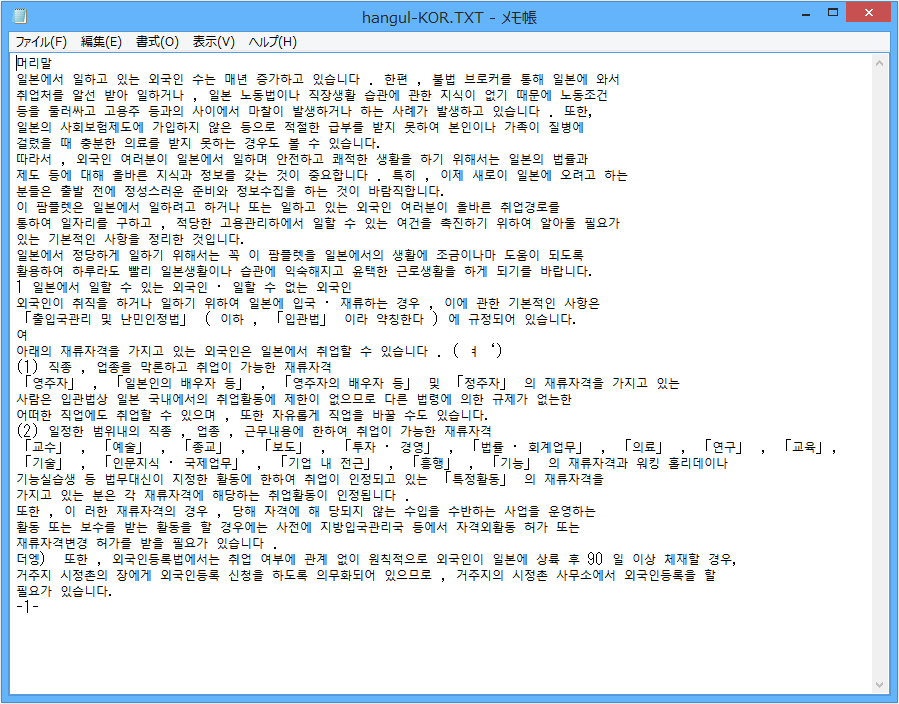
※クリックで拡大

